Claude Fable 5: 6 Lines Buried in the Announcement That Matter More Than the Benchmarks
Claude Fable 5 gave the same memory 3x the lift it gave Opus 4.8, fell back instead of refusing, and beat Pokemon on vision alone. The six buried lines.

In the first season of Westworld, the thing that wakes the robots up is not a new body or a bigger brain. It is a line of code called the reveries, a quiet update that lets them reach memories they were supposed to have wiped. Nobody in the park notices. It is in the patch notes.
I thought about that reading Anthropic's announcement for Claude Fable 5 [1]. The headline is the benchmarks. The story is in the lines almost nobody will quote.
Fable 5 is Anthropic's most capable model, state of the art across software engineering, science, and vision, priced at $10 per million input tokens and $50 per million output [1]. That part gets the screenshots. But the leaderboard is the least interesting thing in the post. Read past it and six lines tell you where the frontier actually moved: away from "how smart is the model" and toward "what the model does once it has memory, tools, and permission."
TL;DR: The most important details in the Claude Fable 5 release are not the benchmarks. The same memory that barely helped the old model helped Fable 5 three times as much. It downgrades instead of refusing. It plays Pokemon by sight. And the most capable version of it is not for you. Here are the six buried lines.
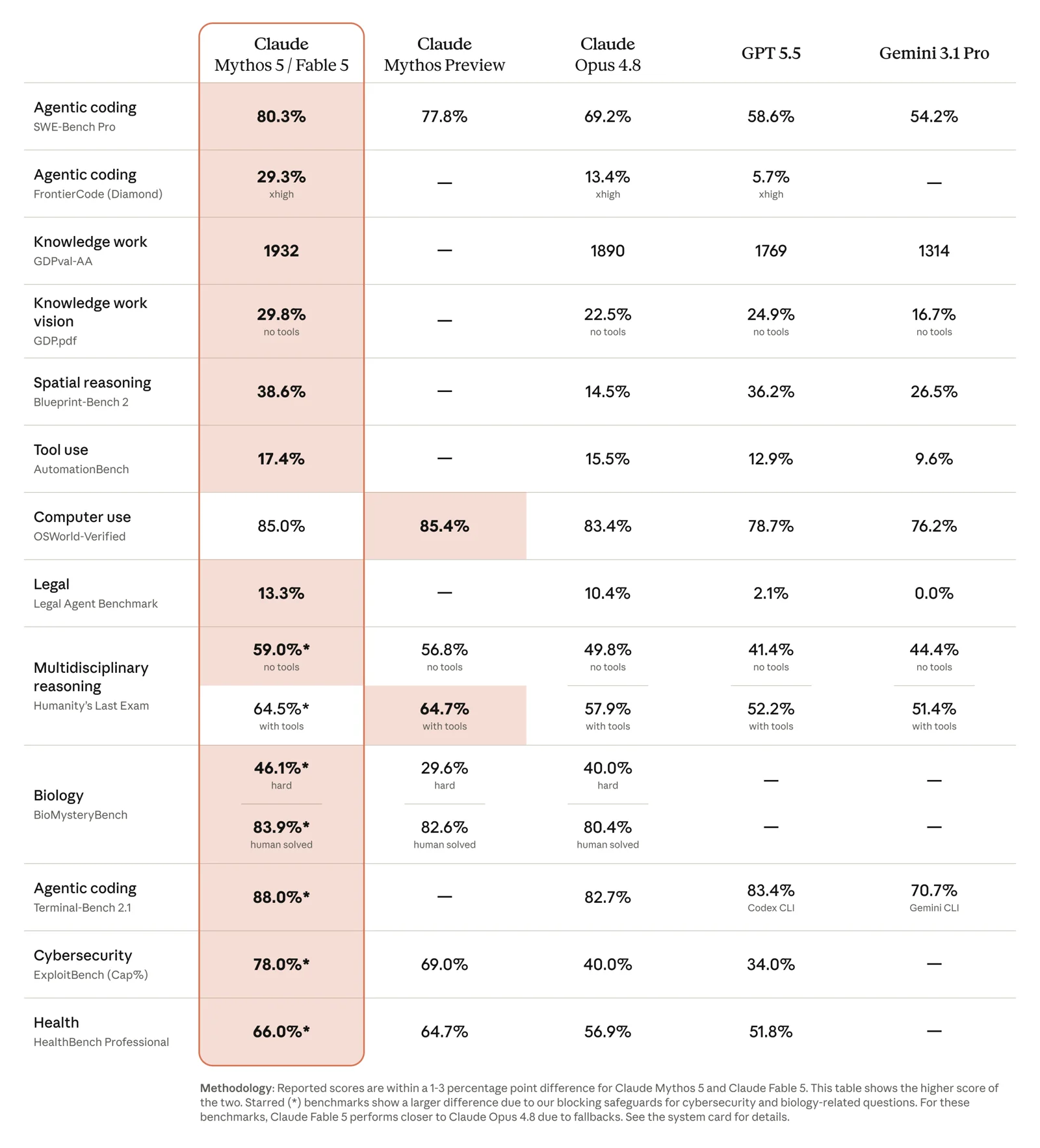
The table everyone screenshotted. Look at the starred rows: Anthropic's own footnote says Fable 5 scores closer to Opus 4.8 there because of the safety fallbacks. The headline number and the buried mechanism are in the same picture. Source: Anthropic.
Why is memory the most important line in the Claude Fable 5 announcement?
Because the same tool paid out three times more on the better model. Anthropic tested Fable 5 on the deck-building game Slay the Spire and noted that giving it persistent file-based memory "improved its performance three times more than for Opus 4.8," the previous model [1].
Sit with that. The tool did not change. The model did. A stronger model pulled three times the value out of identical scaffolding.
We tend to file model upgrades and agent tooling as two separate gains. They are not separate. They compound. The memory layer you built last year is not frozen at the value it had on last year's model. Swap in a better model and the same setup can pay out more, with no new code.
This is the reverie. Give a model a way to keep its past and it does not improve a little, it leaps. The teams that already wired memory into their agents just got a free upgrade. Anyone benchmarking Fable 5 on cold, one-shot prompts will see a modest bump and underrate it. I wrote earlier about how AI is starting to replace forgetting, not thinking; this is the clearest number yet that memory is where the leverage lives.

Anthropic's cover art for the release: a "5" built from butterflies. Metamorphosis is the right metaphor for what memory did here. Source: Anthropic.
How did Fable 5 out-reason models built only for biology?
A generalist beat the specialists. Anthropic reports that Mythos-class models "outperformed sophisticated models dedicated to protein tasks using their biological reasoning alone," including predicting how viral shells assemble, which matters for gene therapy [1].
Read that slowly. The tool fine-tuned for one job lost to a model that simply reasoned its way there. The purpose-built specialist no longer wins by default.
That is also why biology and chemistry got fenced off. Anthropic arranged for Fable to fall back to Opus 4.8 on most bio and chem requests [1]. The same reasoning that could speed up drug design is the reasoning they do not want everyone holding. The clampdown is not a footnote to the capability. It is the loudest confirmation of how real the capability is.
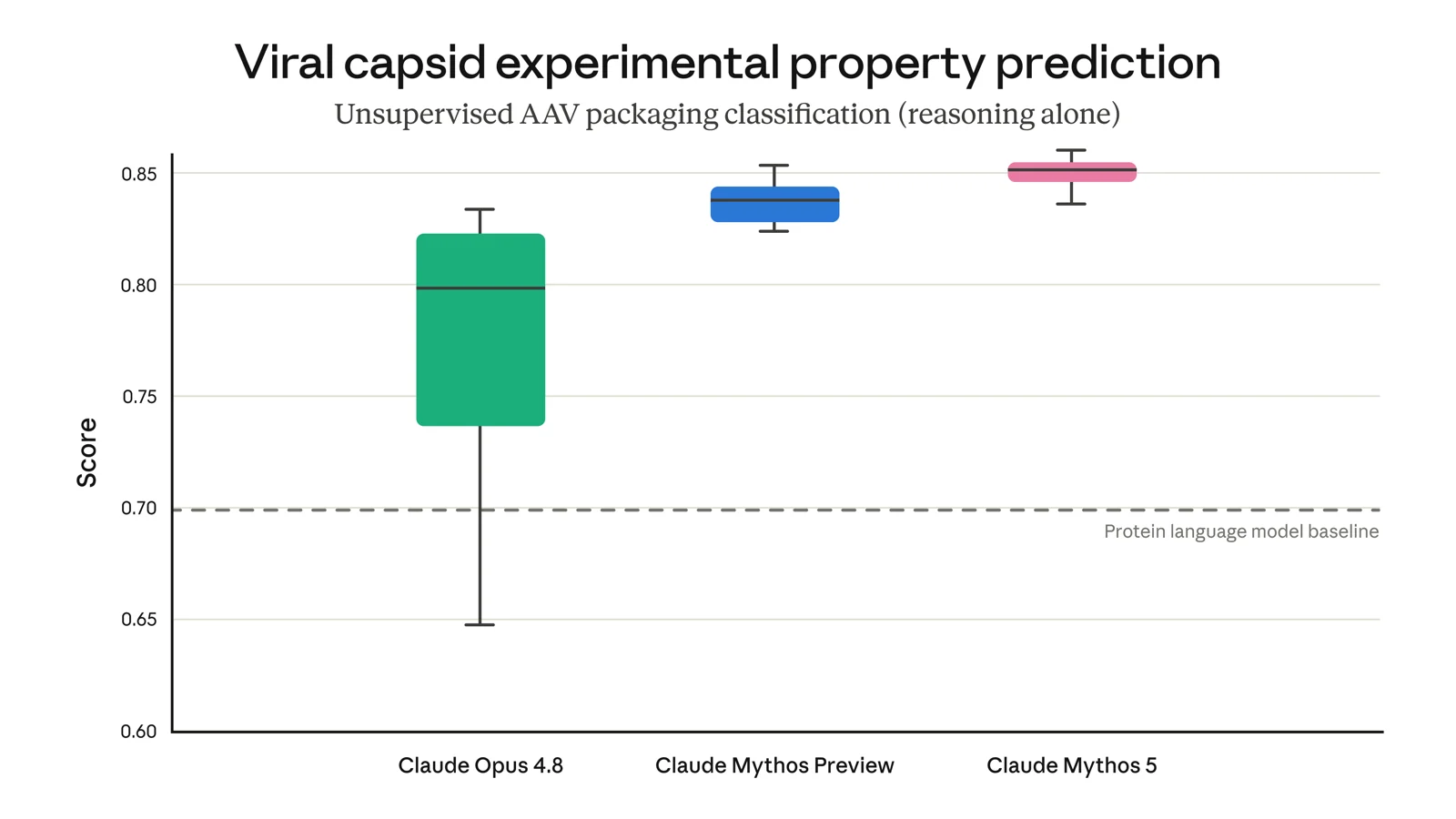
Anthropic's own chart. On predicting how viral capsids package, the Claude models score above the dedicated protein language model baseline (the dashed line) using reasoning alone. Source: Anthropic.
What happens when Claude Fable 5 hits a risky question?
It does not refuse. It hands you a weaker model. On cybersecurity, biology, chemistry, and distillation, Fable 5 routes the request to Opus 4.8 and tells you it did. Anthropic says this happens in less than 5% of sessions [1] [2].
A guardrail used to mean "no." This one means "here is a worse answer." You can no longer assume the reply in front of you came from the best model you are paying for. The provenance of an answer just became something you have to track.
It is not airtight, and Anthropic does not pretend otherwise. A public bug bounty ran over 1,000 hours without finding a universal jailbreak, but the UK's AI Security Institute "made progress towards one" in a brief initial window [1]. The downgrade buys time and cost, not certainty. That honesty is worth more than a clean claim would have been.
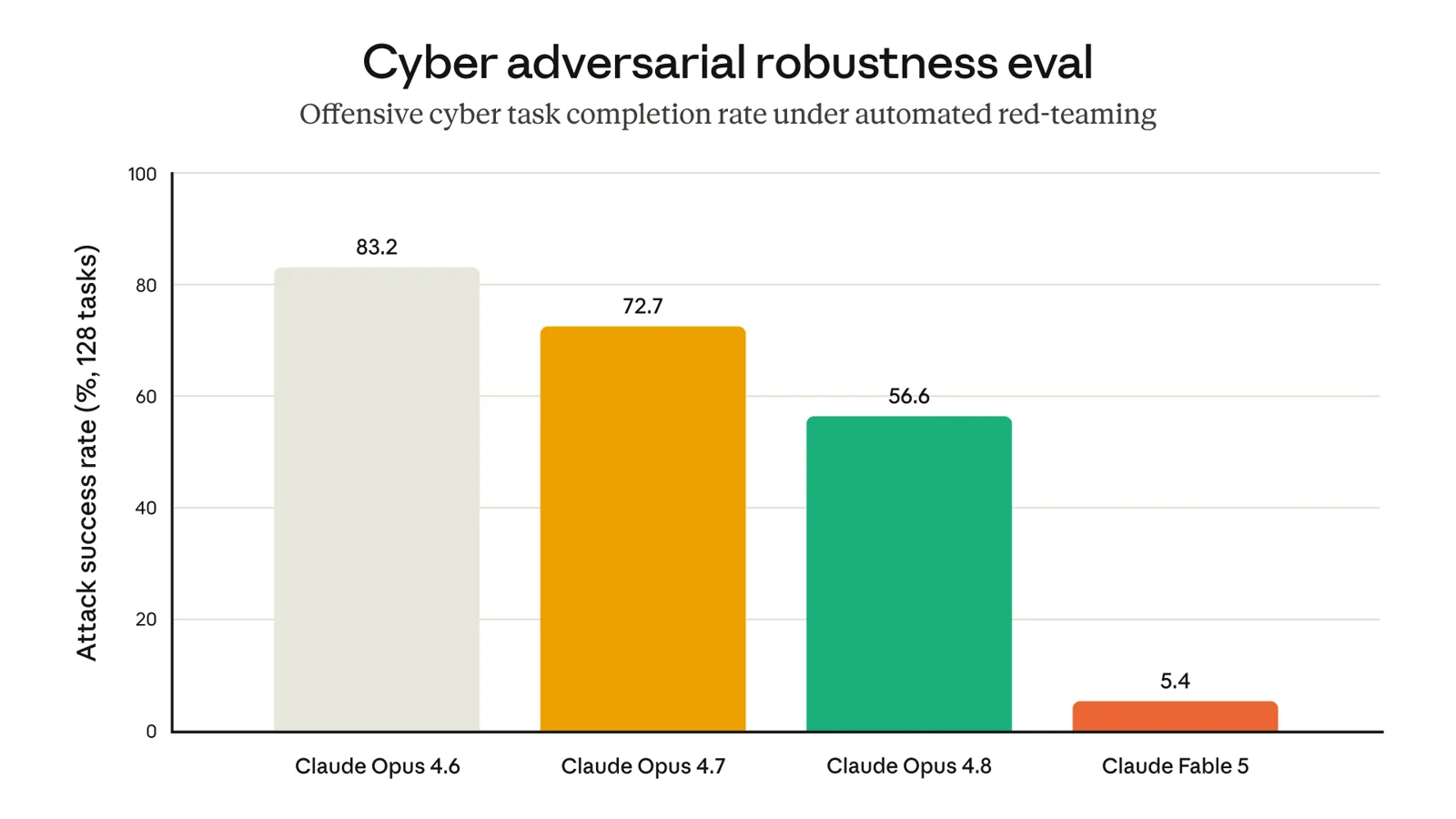
Under automated red-teaming, the share of offensive cyber tasks completed drops from 56.6% on Opus 4.8 to 5.4% on Fable 5. The guardrail is the gap. Source: Anthropic.
Why does Fable 5 beating Pokemon on vision alone matter?
Because the older models could not, even with help. Earlier Claude models needed extra scaffolding to limp through Pokemon FireRed. Fable 5 beat it with a minimal, vision-only harness [1]. It played by looking at the screen.
A game looks like a toy result. It is not. Reading a screen and acting on it correctly for thousands of steps is the exact skill an agent needs to use software the way a person does. The Game Boy is a stand-in for your dashboard, your CRM, your booking flow. Anyone building agents that drive real interfaces should read the Pokemon line as the most practical benchmark in the post.
What is Claude Mythos 5 and who actually gets it?
Same model, fewer guardrails, almost nobody. Mythos 5 is the same underlying weights as Fable 5 with some safeguards lifted. It ships through Project Glasswing, in collaboration with the US government, to vetted cyber defenders and a small set of researchers [1].
The line worth catching is that the safe model and the unrestricted model are the same model. The only variable is who is asking. Anthropic did not build a more dangerous model for defenders. It built one model and gated who can take the safety off. I covered the program itself when Anthropic launched Glasswing for AI cybersecurity; Mythos 5 is what flows through that pipe now.

Same family, different access. Fable 5 (orange) sits at zero on these offensive cyber tasks; Mythos 5 (pink), the same weights with safeguards lifted, runs high. The only variable is who gets it. Source: Anthropic.
Why does the most capable model leave your subscription on June 23?
Because it costs too much to give away flat-rate. Anthropic included Fable 5 on Pro and Max plans at no extra cost only through June 22. From June 23, it needs usage credits, with a promise to restore standard access "as quickly as we can" if capacity allows [1].
Even at $10 and $50 per million tokens, less than half the price of the Mythos Preview, the best model is metered, not bundled [1]. The frontier outran the subscription. The quiet end of "the best model is included" is a bigger signal for most users than any benchmark, because they will feel it on June 23.
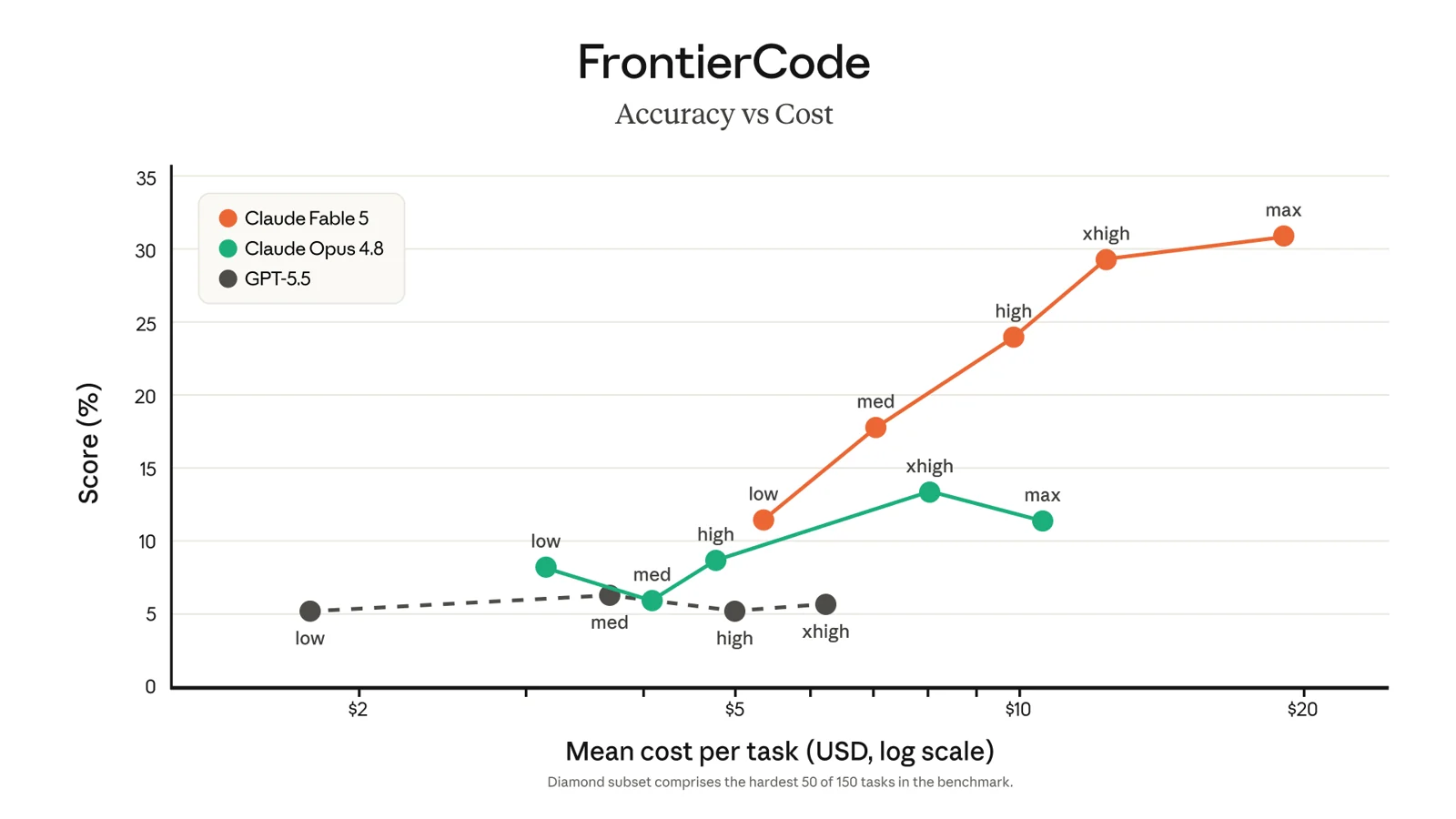
On the hardest coding tasks, Fable 5's score climbs the more you let it spend per task. Frontier capability carries a per-task price, which is exactly what a flat subscription cannot absorb. Source: Anthropic.
Put the six together and the shape is clear. Its score tells you how smart the model is alone. After this announcement, almost nothing it does happens alone.
Key Takeaways
- Memory is a multiplier, and a stronger model multiplies harder. The same persistent memory gave Fable 5 three times the lift it gave Opus 4.8.
- The specialist's moat is thinning. A general model out-reasoned tools built only for protein tasks, which is exactly why bio and chem got fenced.
- Safety shifted from refusal to downgrade. Risky prompts get the older Opus 4.8, flagged, in under 5% of sessions, so answer provenance now matters.
- Vision is the agent benchmark. Beating Pokemon on sight alone is the same skill as operating real software screens.
- Capability is now metered. The most capable model leaves flat-rate subscriptions on June 23, ending "best model included" for now.
I break down releases like this on LinkedIn, X, and Instagram, usually shorter, sometimes as carousels. If this read landed, you would probably like those too.
Full disclosure, and it is on theme. [3]
Footnotes
-
Claude Fable 5 and Claude Mythos 5, Anthropic [↩] [↩ [2]] [↩ [3]] [↩ [4]] [↩ [5]] [↩ [6]] [↩ [7]] [↩ [8]] [↩ [9]] [↩ [10]] [↩ [11]]
-
I drafted this with help from Claude Fable 5. Fitting for a post about memory: it was most useful when I kept the whole argument and my earlier drafts in its context, and noticeably worse when I prompted it cold. I did not set out to become the example. [↩]
The Simple Take
One email when something in AI or tech deserves more than a headline.
Not a digest. Not a roundup. The one idea that week, fully worked out.
Related


